VISA 笔记
VISA 论文简记
1. 这篇文章做了什么
这篇文章提出了一个新任务:ReasonVOS(推理式视频目标分割)。
和传统 VOS / Referring VOS 不一样的地方在于:
它不是分割那种“外观很明确”的目标,而是分割需要推理才能确定的目标,比如:
- 哪辆车最可能赢
- 哪个交通工具载客量最大
- 那只狗害怕什么
也就是说,这篇文章想做的是:
把“视频理解 + 世界知识推理 + 像素级分割”结合起来。
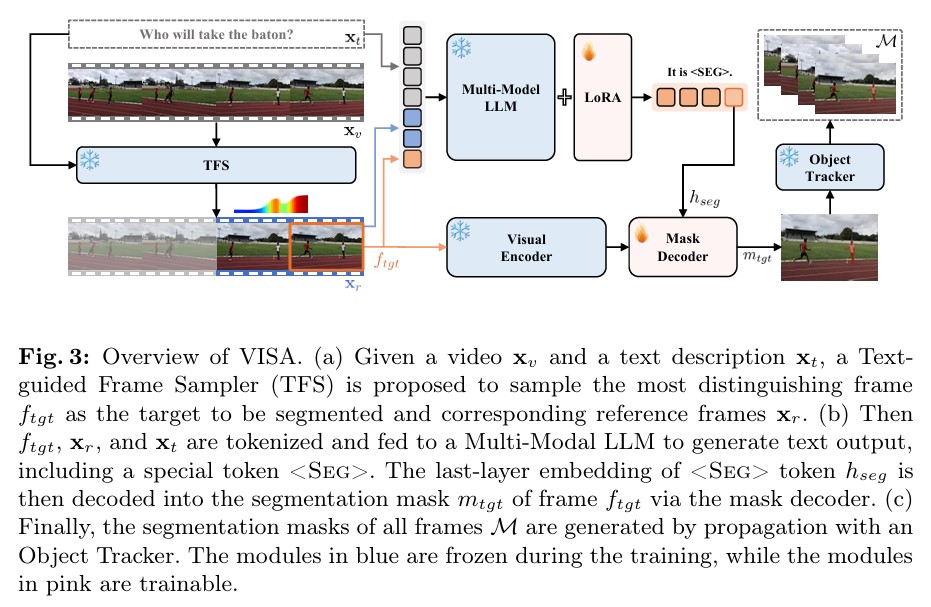
2. 核心思路
作者提出了一个框架:VISA
全流程可以概括成:
1 | 文本指令 + 视频 |
它不是直接把整个视频全丢给 LLM,而是先缩小范围,再做推理和分割。
3. VISA 的主要模块
(1) TFS:Text-guided Frame Sampler
作用:先找最关键的帧
因为长视频帧太多,如果每帧都高质量输入 LLM,token 太多,算不动。
所以作者先用一个文本引导的采样器,根据问题判断:
- 视频中大概哪一段最相关
- 选出一个 target frame (
f_tgt) - 再选一些 reference frames (
x_r)
这里用到的是 LLaMA-VID,本质上相当于让模型先回答:
“为了找到这个目标,我应该看视频的大概百分之多少位置?”
(2) Multi-Modal LLM
作用:根据目标帧 + 参考帧 + 文本,推理目标是谁
选中的帧先编码成视觉 token,再和文本一起输入多模态 LLM。
模型输出一句话,其中包含一个特殊 token:
1 | <Seg> |
这个 <Seg> 不是普通文字,而是表示:
“我已经知道要分割谁了”
作者取出 <Seg> 对应的最后一层 hidden state,得到一个目标语义表示 h_seg。
(3) Mask Decoder
作用:把“目标语义”变成目标帧上的像素掩码
这里作者用了 SAM 的 decoder。
输入是两部分:
- 目标帧的视觉特征
<Seg>产生的语义提示h_seg
然后输出目标帧的分割结果:
m_tgt
所以这一部分本质上是:
LLM 负责决定“是谁”,SAM 负责决定“像素在哪”
(4) Object Tracker
作用:把目标帧掩码传播到整个视频
因为前面只分割了一个目标帧,所以还要把这个结果扩展到其他帧。
作者这里用了 object tracker(文中是 XMem 风格的方法),做双向传播,最后得到整段视频的 mask sequence。
4. 训练是怎么做的
训练时不是所有模块都训,而是冻结大部分 backbone,只训练少数模块。
主要是:
- 大模型主体基本冻结
- 用 LoRA 做轻量微调
- 训练 mask decoder / MLP 这些和分割有关的部分
损失函数有两部分:
- 文本生成损失:让模型学会输出正确回答和
<Seg> - 分割损失:让生成的 mask 更准(BCE + Dice)
所以它本质上是一个:
“语言生成监督 + 分割监督”联合训练 的框架
5. 这篇文章用了哪些关键技术
可以直接记这一串:
- LLaMA-VID:做关键帧选择(TFS)
- LLaVA / Chat-UniVi:做多模态推理
- ViT:提取视觉特征
- Spatial Merging:压缩视觉 token
- LoRA:参数高效微调
- SAM decoder:生成目标帧掩码
- XMem / Object Tracker:传播到整段视频
本质上是把:
视频检索关键时刻 + LLM 推理 + SAM 分割 + Tracker 传播
串成了一条链。
6. 关键点
- 提出了新任务 ReasonVOS:不是显式描述分割,而是推理式视频分割
- 提出了 VISA:先找关键帧,再让 LLM 推理,再用 SAM 分割,再用 tracker 扩展到全视频
- 关键创新点:用
<Seg>把 LLM 的推理结果转成可用于分割的提示表示
极简一句话版
VISA = TFS 选关键帧 + 多模态 LLM 推理目标 + <Seg> 作为分割提示 + SAM 出目标帧 mask + Tracker 扩展到整段视频。
