ViLLa 笔记
这篇文章做的是视频推理分割,也就是给模型一段视频和一句比较复杂的文本指令,让它不仅要看懂视频,还要结合语言去推理“目标到底是谁”,最后把这个目标在视频每一帧里分割出来。它和普通的 referring VOS 不一样,普通任务里的文本通常比较直接,比如“左边的人”或者“红色的车”,而 ViLLa 面对的是更复杂、更接近真实用户表达的描述。
这篇文章的核心目标,是解决前面一些方法在复杂视频场景里的问题。作者认为,以前的方法在简单视频上还能用,但一遇到长视频、多目标、快速运动、遮挡这些情况,就容易出问题。比如 VISA 很依赖关键帧选得准,如果一开始选错了,后面传播就会越错越多;VideoLISA 虽然做了视频建模,但它的采样方式不够自适应,而且单个分割 token 在复杂场景下不太能同时处理好多目标和它们的轨迹关系。
所以 ViLLa 提出了三个核心模块,分别从不同角度解决这些问题。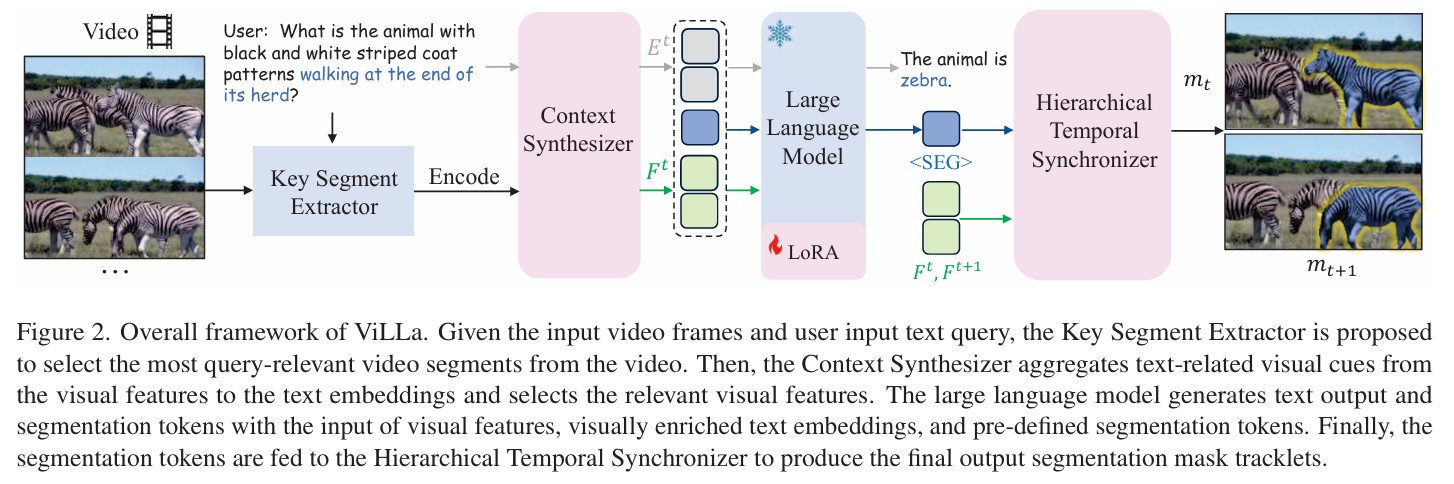
第一个模块叫 Key Segment Extractor,也就是关键片段提取器。它的作用很直接,就是先从长视频里挑出和问题最相关的片段。作者的想法是,长视频里很多内容其实和当前问题没关系,没有必要全都送进去。比如用户问“走在兽群最后面的那只斑马”,真正有用的信息只会出现在某些特定时刻。所以它先用一个视频大模型去预测和 query 最相关的起止时间段,再把这部分关键片段抽出来。这样做可以减少冗余,也让后面的模型更集中地处理有用信息。
第二个模块叫 Context Synthesizer,也就是上下文合成器。这个模块主要是做文本和视觉的对齐,而且不是简单对齐,而是把“和当前问题最相关的视觉信息”注入到文本表示里。你可以理解成,模型先看用户到底在问什么,再从当前帧的视觉特征里找出最相关的线索,比如位置关系、外观、动作这些信息,然后把这些信息融合进文本 embedding。这样送进 LLM 的就不是单纯的文字,而是已经带有当前视觉上下文的文字表示。作者还进一步做了压缩,不是把所有 query 都送给 LLM,而是只保留响应最高、最相关的那几个,让输入更紧凑。
第三个模块是这篇文章最重要的部分,叫 Hierarchical Temporal Synchronizer,也就是分层时间同步器。这个模块是专门为视频设计的,因为视频分割最难的地方不只是“这一帧分对”,还要“前后帧都一致”。作者这里设计了两种层级的 segmentation token,一种是帧级 token,主要关注当前帧里的目标;另一种是视频级 token,主要关注整个视频范围里的目标身份和整体信息。然后通过一个类似 transformer decoder 的结构,让这两类 token 在时间维度上不断交互、同步。帧级 token 提供细节,视频级 token 提供整体一致性,二者反复融合之后,最后得到更稳定的分割表示。这样做的好处是,在多目标、遮挡、快速运动这些复杂情况下,模型不会只盯着当前帧的局部信息,而是能同时参考整段视频里的目标信息。
整个 ViLLa 的流程其实可以概括成一条很清晰的链。先输入视频和文本指令,然后关键片段提取器从长视频里找到和问题最相关的部分;接着视觉编码器提取这些片段的多尺度视觉特征,同时文本编码器把文本和视觉做初步对齐;然后上下文合成器把和问题最相关的视觉线索融合进文本表示;再把这些增强后的文本特征、视觉特征和预定义的分割 token 一起送进大语言模型;大语言模型一边输出文本回答,一边输出分割 token;最后这些 token 再进入分层时间同步器,结合多尺度视觉特征,生成每一帧的分割结果。
训练的时候,这个模型是端到端训的,既有文本生成损失,也有分割损失。也就是说,模型不仅要学会“回答得对”,还要学会“分割得准”。分割损失同时约束视频级和帧级表示,所以它不是只训练单帧分割能力,而是在训练时就显式让模型学会跨帧的一致性。
除了方法本身,这篇文章还自己构建了一个新数据集,叫 VideoReasonSeg。这个数据集就是为了专门评估视频推理分割而做的,里面既有分割标注,也有多项选择题形式的问答。作者这样设计,是因为如果全都用开放问答来评估,容易引入大模型评分偏差;而多项选择题更稳定,更好量化推理能力。这个数据集里同时包含短视频和长视频,也专门覆盖了多目标、快速运动和长视频遮挡这些复杂场景。
ViLLa 想解决的是复杂视频里的推理分割问题,它不是简单地把图像推理分割搬到视频上,而是专门加入了关键片段选择、文本视觉上下文融合,以及视频级和帧级 token 的时间同步这三步。前两步解决“看什么”和“怎么理解”,最后一步解决“怎么在整段视频里稳定地分出来”。
