VRS-HQ 笔记
- 1. 《The Devil is in Temporal Token: High Quality Video Reasoning Segmentation》读文笔记
《The Devil is in Temporal Token: High Quality Video Reasoning Segmentation》读文笔记
1. 文章主题
这篇文章研究的是 Video Reasoning Segmentation(VRS,视频推理分割)。
任务输入是一段视频和一句带有推理性质的文本,输出是视频中目标在每一帧上的分割 mask。
和传统的 referring video object segmentation 不同,VRS 的文本往往不是直接描述外观,而是带有 时序关系、语义推理或常识推理,例如:
- 视频最后只露出尾巴的猫
- 靠风驱动的物体
- 最后时刻仍在飞的鸟
因此,这个任务不仅要求模型会做分割,还要求它能结合 空间信息、时间动态和语言推理 去定位目标。
2. 文章想解决的问题
作者认为现有 VRS 方法主要有三个不足。
2.1 单一 special token 表达能力不足
已有方法通常使用一个特殊 token 来表示目标物体,再基于这个 token 做关键帧分割或整段视频传播。
但一个 token 很难同时承载:
- 帧内的细粒度空间信息
- 帧间的动态变化信息
- 整段视频中的全局语义信息
所以容易出现目标表示不充分的问题。
2.2 关键帧选择不准确
像 VISA 这类方法需要借助外部模型进行关键帧选择。
如果视频中的目标需要复杂时间推理才能判断,那么外部模型选出来的关键帧不一定真的最适合分割。
2.3 分割与传播割裂,不能端到端
先做关键帧分割,再调用另一个外部跟踪/传播模型,这种设计会让整个流程变成分阶段处理,训练和推理都不够统一。
3. 核心思路
这篇文章的核心思想是:
不再只用一个 token 表示整个视频中的目标,而是同时构建 帧级 token 和 视频级 token,并通过时序聚合把它们融合起来,再利用这个融合后的 temporal token 去完成关键帧选择、关键帧分割和跨帧传播。
作者提出的方法叫 VRS-HQ,关键模块包括:
- Temporal Token Encoding
- Temporal Dynamic Aggregation(TDA)
- Token-driven Keyframe Selection(TKS)
- Mask Decoding and Propagation(基于 SAM2)
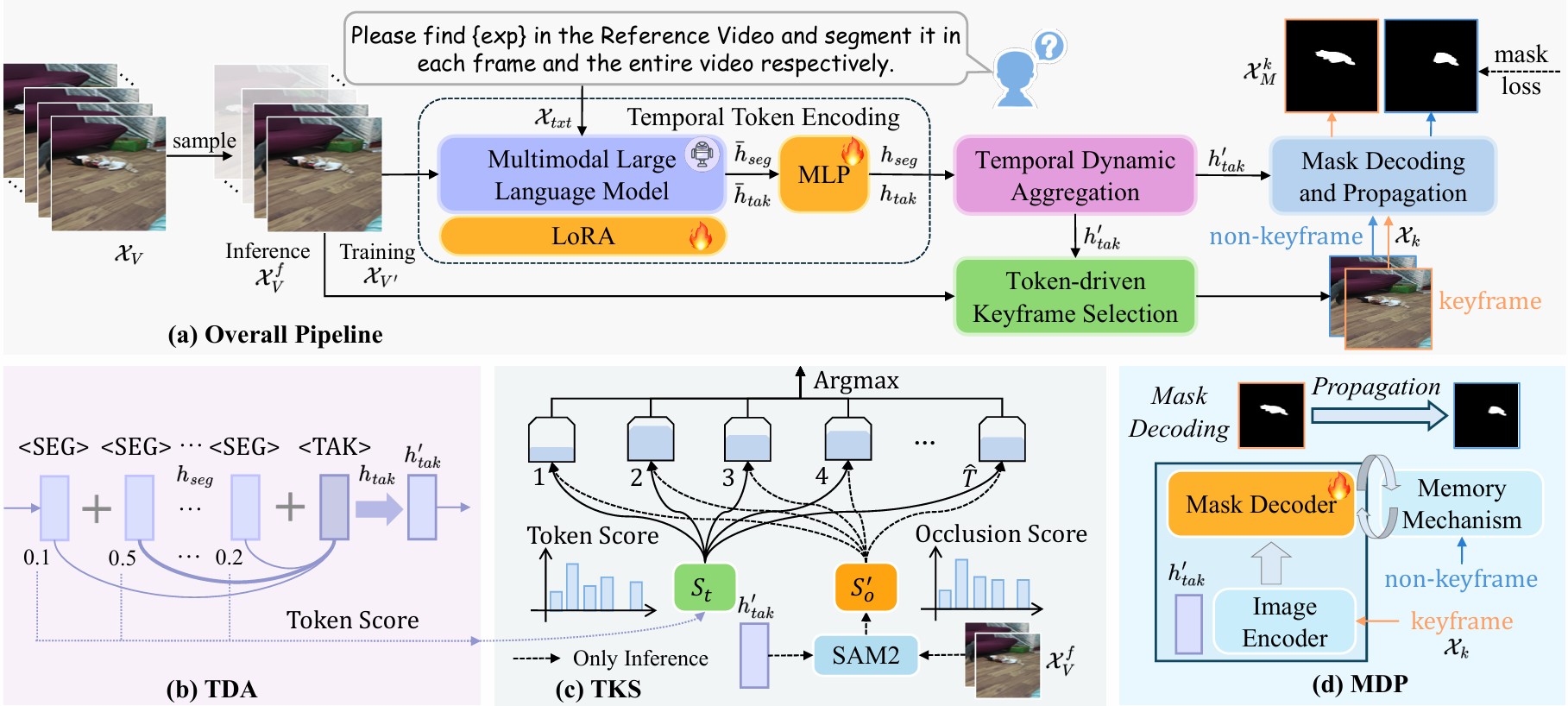
4. 整体流程
整篇方法可以概括为四步:
Step 1:输入视频和文本,生成分层 token
将采样的视频帧和文本提示送入 MLLM,生成两类 token:
<SEG>:帧级 token,每一帧对应一个,表示该帧中的目标信息<TAK>:时间级 token,只有一个,表示整段视频中的全局目标语义和时序信息
这里的设计思想是把目标表示拆成两个层次:
<SEG>偏向局部、空间、单帧<TAK>偏向全局、时间、整视频
Step 2:通过 TDA 融合帧级信息与视频级信息
作者提出 Temporal Dynamic Aggregation(TDA),用来把多个 <SEG> token 中的信息融合到 <TAK> 中。
具体做法是:
- 计算每个
<SEG>与<TAK>的余弦相似度 - 将相似度作为权重
- 对所有
<SEG>做加权求和 - 再把这个加权结果加到
<TAK>上
于是得到一个新的融合后 token,记作 ( h’_{tak} )。
这个 token 不再只是一个抽象的“视频级语义向量”,而是同时吸收了:
- 帧级空间细节
- 帧间语义一致性
- 视频级时间上下文
Step 3:通过 TKS 选择关键帧
作者提出 Token-driven Keyframe Selection(TKS),让 temporal token 直接参与关键帧选择。
训练时
训练阶段使用一种较简单的策略:
- 计算每一帧
<SEG>与融合后<TAK>的相似度 - 选择与
<TAK>最接近的帧作为关键帧
也就是说,谁最能代表整段视频的目标语义,谁就是关键帧。
推理时
推理阶段更复杂一些:
- 先用 CLIP 找到与文本表达最相关的 anchor frame
- 围绕这个 anchor 进行采样,得到候选关键帧
- 把每个候选帧与融合后的
<TAK>一起输入 SAM2 - 由 SAM2 输出每一帧的 occlusion score(遮挡分数)
- 再结合 token similarity 和 occlusion score 来决定最终关键帧
这里的关键点是:
作者不再把关键帧选择交给一个外部独立模块,而是让模型内部的 temporal token 和 SAM2 共同参与判断。
Step 4:基于 SAM2 做关键帧分割与全视频传播
在选出关键帧后,作者使用 SAM2 完成后续处理。
具体包括两部分:
关键帧分割
将关键帧图像特征和融合后的 <TAK> token 一起输入 SAM2 的 mask decoder,生成关键帧 mask。
跨帧传播
再利用 SAM2 自带的 memory mechanism,把关键帧 mask 传播到其他帧,得到整段视频的 mask 序列。
这一步的重要意义在于:
- 分割和传播统一到同一个框架中
- 不再需要单独的 tracker
- 更接近端到端推理
5. 各个模块的作用
5.1 Temporal Token Encoding
这是方法的输入编码阶段。
它的作用是让 MLLM 不只输出一个表示目标的 token,而是输出:
- 多个帧级
<SEG>token - 一个视频级
<TAK>token
这样做的目的,是把 局部空间信息 和 全局时序语义 分开建模。
我理解这一部分的核心思想是:
视频任务中,目标不仅要“知道是谁”,还要“知道在不同帧里怎么变化”,所以必须把单帧和整段视频两个层面的信息都显式表示出来。
5.2 Temporal Dynamic Aggregation(TDA)
这是本文最核心的模块之一。
它的作用是把多个 <SEG> token 的信息,通过相似度加权的方式融合进 <TAK> 中。
这样得到的融合 token 既保留了视频级目标语义,又补充了帧级目标的细节信息。
作者希望通过这个模块实现两点:
- 增强 temporal token 对时序动态的建模能力
- 提升 token 对目标位置和外观变化的感知能力
换句话说,TDA 让 <TAK> 不再只是“全局语义标签”,而是变成一个真正能驱动视频分割的 token。
5.3 Token-driven Keyframe Selection(TKS)
这是另一个核心模块。
它的作用是:
让关键帧选择直接由 token 驱动,而不是依赖外部模型。
作者认为,关键帧必须满足两个条件:
- 从语义上最能代表整段视频目标
- 从视觉上目标要尽可能清晰、可分割
因此,TKS 同时利用:
- token similarity:衡量语义代表性
- occlusion score:衡量当前帧目标是否可见、是否适合作为关键帧
这个设计相比传统关键帧选择更贴近最终任务目标,因为它直接服务于后续的分割和传播。
5.4 Mask Decoding and Propagation
这一部分基于 SAM2 完成。
它的作用是:
- 在关键帧上解码 mask
- 将关键帧结果传播到全视频
这部分的贡献不在于提出了新的分割器,而在于把前面学到的 temporal token 与 SAM2 结合起来,使得:
- temporal token 成为视频分割的引导信号
- SAM2 负责高质量分割和时序传播
- 整个流程形成统一闭环
6. 方法的逻辑主线
我觉得这篇文章的方法主线非常清晰,可以概括为下面这条链路:
文本 + 视频帧
→ MLLM 生成帧级 <SEG> 和视频级 <TAK>
→ TDA 融合得到更强的 temporal token
→ TKS 用 temporal token 选择关键帧
→ SAM2 用 temporal token 做关键帧分割并传播到全视频
所以这篇文章真正强调的是:
temporal token 不是只拿来“表示目标”的,而是贯穿了目标建模、关键帧选择、分割和传播整个过程。
这也是题目里 “The Devil is in Temporal Token” 想表达的重点。
7. 文章的核心贡献
如果用读书笔记式的话总结,这篇文章的贡献可以写成三点:
(1)提出分层 token 表示
用帧级 <SEG> 和时间级 <TAK> 替代传统单 token 表示,使目标表示更适合视频任务。
(2)提出 TDA
通过相似度加权融合,把帧级 token 的空间细节注入视频级 temporal token,增强其时空表达能力。
(3)提出 TKS,并与 SAM2 结合
利用 temporal token 和 occlusion score 联合进行关键帧选择,再由 SAM2 完成关键帧分割和全视频传播,实现更统一的视频推理分割流程。
8. 我的理解
我觉得这篇文章最关键的 insight 不是“用了 SAM2”,而是:
把 temporal token 从一个静态表示,变成了一个真正驱动视频推理分割流程的核心变量。
以前的方法里,token 更像一个提示符;
而在这篇文章里,token 参与了:
- 目标表达
- 多帧信息聚合
- 关键帧判断
- 掩码解码
- 跨帧传播
所以这篇文章其实是在强化一个观点:
视频推理分割的关键,不只是更强的分割器,而是更强的时序目标表示。
9. 可以直接放在笔记末尾的一句话总结
VRS-HQ 通过构建帧级 <SEG> 与视频级 <TAK> 两类 token,并利用 TDA 进行时序聚合、利用 TKS 进行关键帧选择,最终结合 SAM2 完成关键帧分割和全视频传播,从而提升了视频推理分割中的时空建模能力。
